Vacation Project: Weekend Update
June 22, 2020
I said I was not going to work on this project over the weekend. That was a lie: I pushed a few commits into the repo through the weekend. Last I wrote, I was a bit frustrated by the response structure provided by Athena’s get_query_results() method. This response is a row-based dictionary where each element lists the related columns’ values. It is probably the simplest way to share tabular results that do not have a primary key but it flies in the face against column-oriented data types that have become a modern standard.
Refocusing the effort
Frustrations aside, I am still eager to figure out some type of data orchestration solution to routinely repair the data stream. I am going to scope the effort down to focus on using Step Functions to perform the following data processing steps:
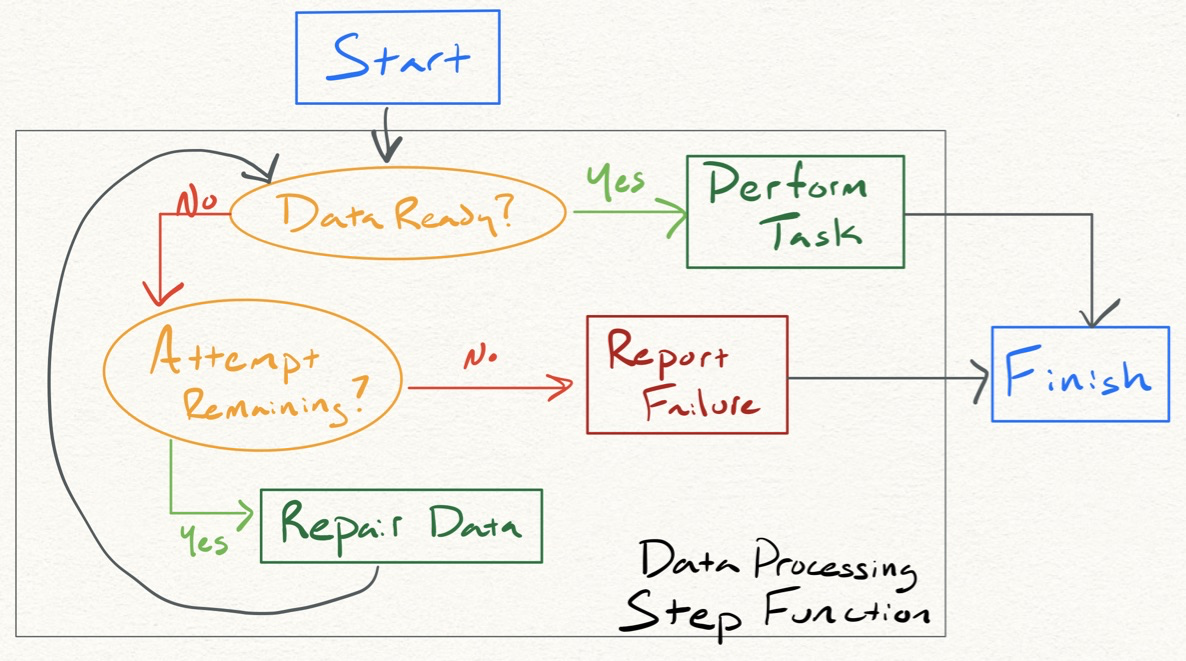
To make it easier, I went ahead and took the dive into AWS Lambda Layers. Contrary to my initial thoughts, Layers are surprisingly easy to incorporate into a serverless app. I can load Pandas as a dependency into the Layer and then let my Lambda Functions rely on said Layer. That results in Pandas being available without overloading my Lambda Function size limits. Now that Layers are in play, I can think of it as ‘Helper Layer’ to also store common methods in one file instead of copy/pasting them into each individual Lambda Function.
Work completed this weekend
I made the following changes/updates between now and my prior post:
- Introduced Lambda Layers into the project that includes:
- A package dependency on Pandas.
- Several abstract ‘helper’ methods such as
get_interested_stocks(),get_environ_variable(),send_to_sqs(), and so on.
- Wrote several new helper methods to help query Athena and obtain results:
generate_data_check_query()to generate a query that will ask Athena to report the missing minutes of data between a start and end range.submit_athena_query()to accept a query and return a query execution ID.wait_for_athena_results()to accept a query execution ID and poll until the query run is complete.get_athena_query_results()to retrieve query results in the row-based dictionary structure.
Coming up next
- A method to parse the results from
get_athena_query_results()and form it into a Pandas data frame. - A method to read the data frame and make a determination if data needs to be repaired.
- Should repair be necessary, I will need functions to both queue up repair jobs and process repair jobs.
- Finally, link everything together with a Step Function.
Additional learning so far
- AWS SAM has been awesome for local build and testing of my AWS Lambda Functions and Lambda Layers. I use PyCharm’s debugger often but I have noticed something weird about debugging methods called from a Lambda Layer. Basically, I cannot ‘step-in’ to Lambda Layer methods as I could with other local files and packages. It has forced me to run often and basically treat the results like a manual unit-test.
- Without proper environments took up, I am doing all my integration tests in production. Opps. Fortunately the intent of this vacation project is to fix data. So even though I caused a few minutes of missing data, the repair operation will fix it up.