Vacation Project: Day Two
June 18, 2020
At this point, all of the infrastructure work is complete and I am pulling stock data every minute for 11 stocks. The biggest additions from yesterday include using a time-triggered Lambda to queue up stock data requests for another Lambda to go get. The results get moved into a data stream then stored in a data lake. Now I have a data catalog available that enables us to query Amazon Athena (serverless query service) to do some basic analytics on the data. The latest hand-drawn monstrosity of an architecture diagram looks like this:
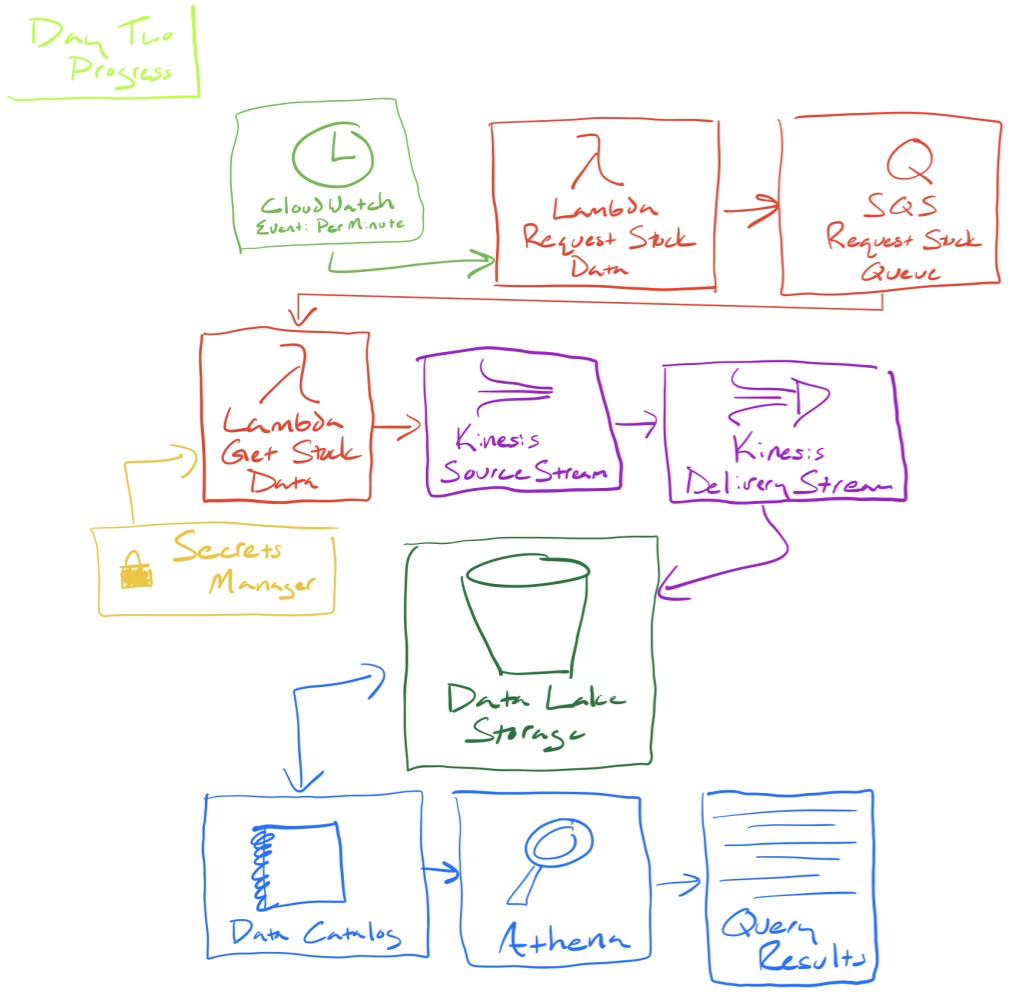
But wait… something is wrong!
This project is an attempt to self-heal data. That means something has to be broken… so I introduced a glitch into how I request stock data:
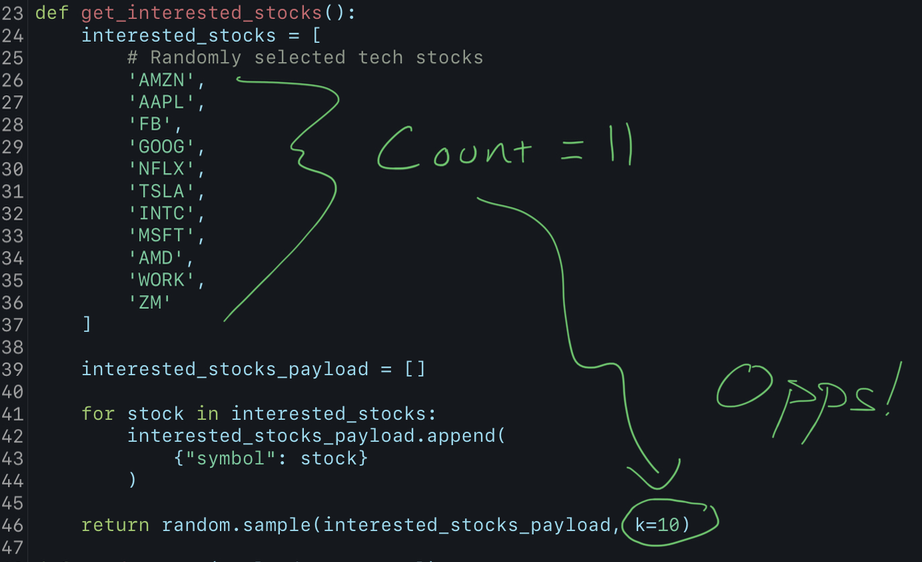
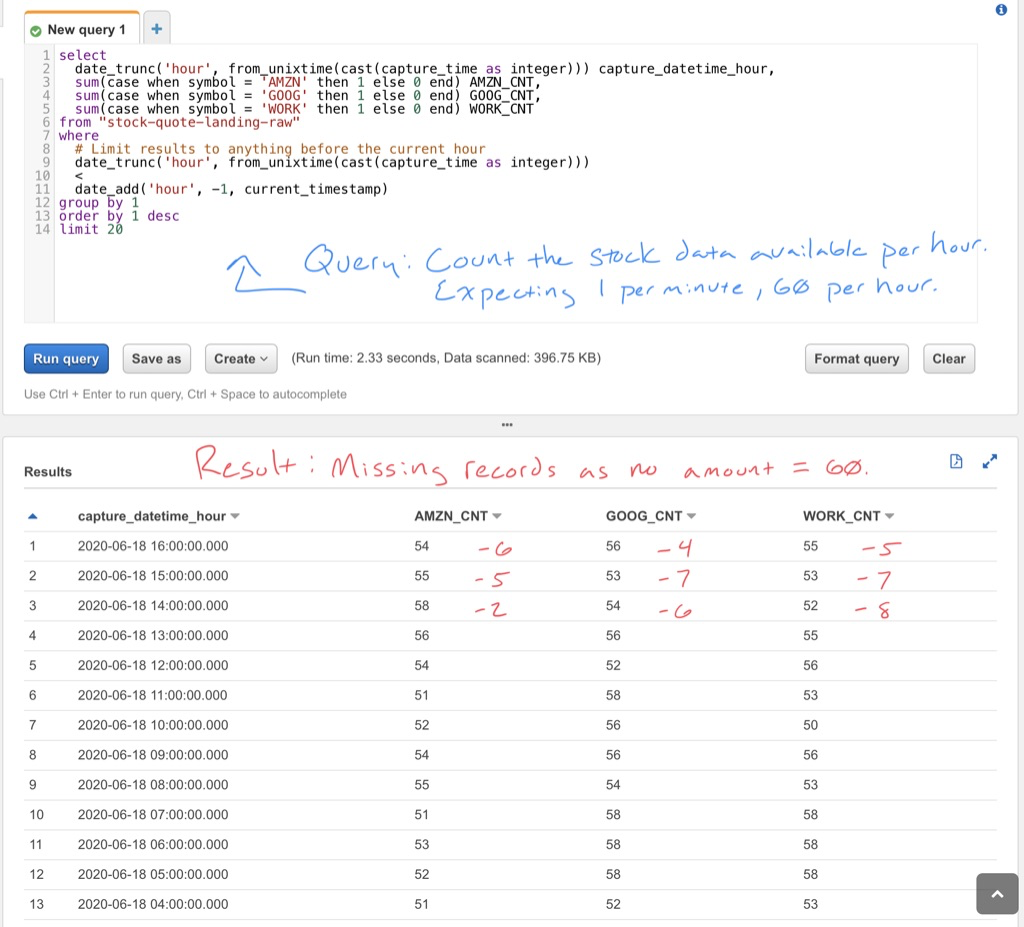
As you can see, the code has 11 stock tickers identified in the interested_stocks list. But when I return the list to the main function for processing, I randomly select 10 of the 11 stocks. This means for any given minute, I will not request one of the interested stocks. If I query the data to see how many hourly data points exist for a given stock ticket, a complete data set would be 60 data points per hour. Yet when I actually query the data, I can see none of the stocks actually have 60 points per hour:
Bad Results Via Amazon Athena
Bad Results Via Amazon QuickSight
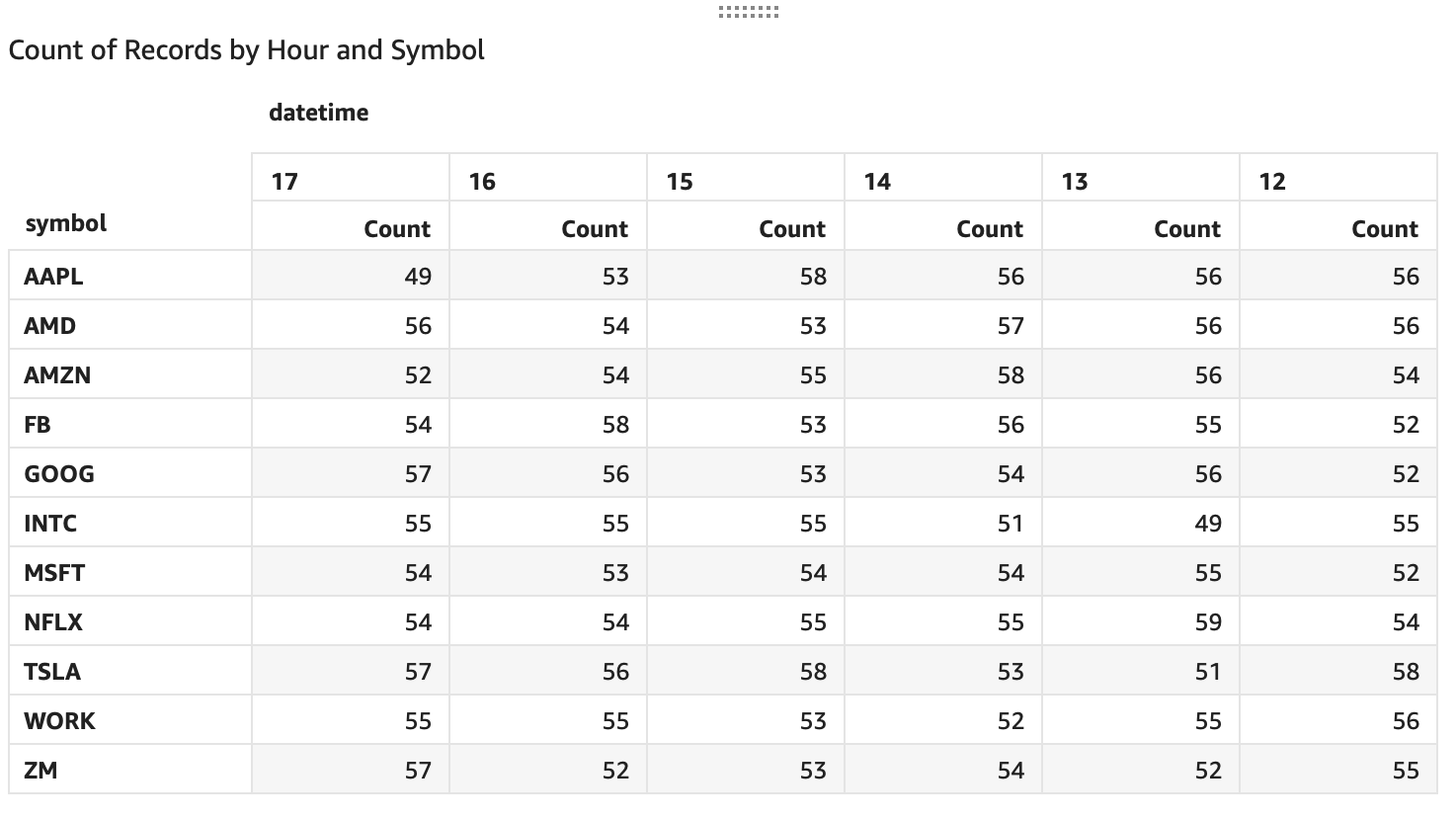
So Now What?
I want to aggregate the data on an hourly basis but only after I repair for the missing records. The “learning” part of this vacation project is to help me think about how to build an abstract solution I could bring to any problem. The challenge I am hitting is that each data challenge I encounter is likely to require its own compute solution for repair.
To avoid getting lost in the specifics of this vacation project problem, I want to think about building a framework to solve similar problems. There are two solutions I could tinker with: AWS Step Functions and AWS Glue Workflow Orchestration. Both solutions let me tackle the problem by beginning a process, declaring operations, and handling waiting/errors. From a quick glance, Step Functions seems to enable me to write a custom processing path (eg: start, wait, go back, skip forward, etc..) whereas Glue Workflows takes a one-way directed acyclic graphs (DAGs) approach (eg: do A, then B, then C, etc..).
All that said, today will be a research day. The only code push I want to make today is to assign tags to everything so I can track costs (related doc). I want to identify the costs for running the infrastructure as well as track costs for each data repair idea separately. This way I could objectively analyze the cost of running the infrastructure code against the costs of running each of the data repair ideas. This could bring out some interesting observations when it comes to making infrastructure fixes versus bolting on repair operations.