Vacation Project: Self-Healing Data Stream
June 16, 2020
Yesterday I started a two-week vacation from Amazon Web Services. While I am excited to take a break, I want to use some of this time to play with AWS technologies I have not yet used. I wanted to go beyond tutorials so I came up with a small project: a self-healing data stream. I will create routine data streams that are processed continuously to create downstream facts and aggregations. The challenge is that the data capture mechanism has an intentional flaw may result in incomplete data sets being used by downstream clients. This requires building an “auditor” to step in, analyze the data sets, and take corrective actions if data quality is impaired.
Planned Data Operations
I will eventually draw a proper diagram, but here is the hand drawn diagram that has helped me shaped up this project:
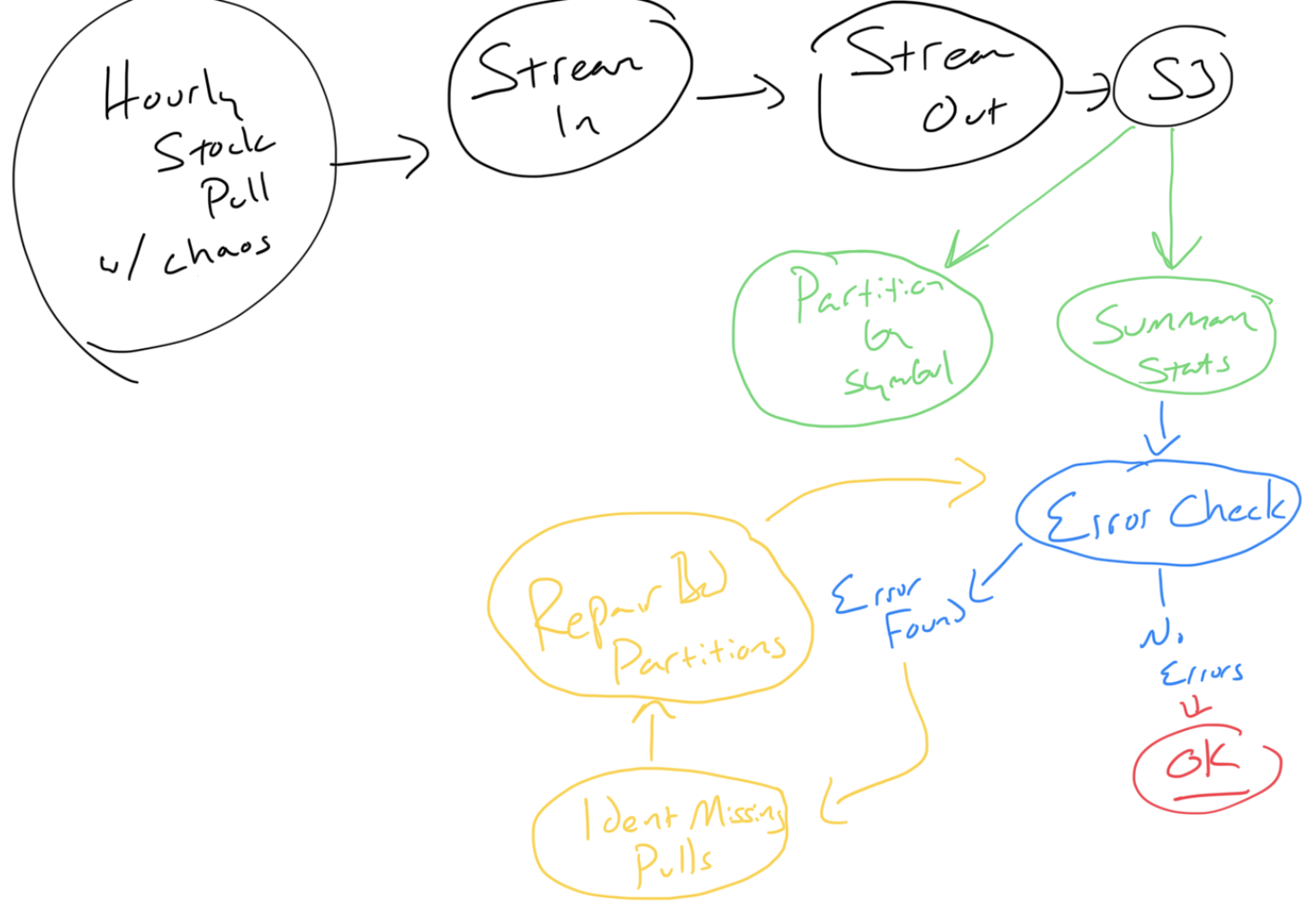
High level operations includes:
- Data Acquisition: Pull some financial stock data on a regular cadence (hour? minute? exact timing TBD), write the payloads into a data stream, store the at rest in S3, then use data lake technologies to enable analytics and downstream processing.
- Data Transformation: Continuously read from the data lake to transform granular data into data sets representing new facts and aggregations. This involves repartitioning the data into partitions that better align with downstream queries (eg: partition by stock symbol as opposed to ingestion time).
- Data Validation: Start an audit process to learn the current state of data quality. Should data quality be impaired, then the audit process should kick off:
- Data Repair: Reuse the Data Acquisition steps to obtain any missing data chunks.
- Data Resynthesis: Reuse the Data Transformation steps to rematerialize transformed data sets impacted by the repair operation.
- Alarm: Fire an alarm if repair and/or resynthesis attempts fail or exhaust their retry attempt count.
Planned Technologies
- Software deployment will most likely be handled via AWS Toolkit in PyCharm. This plug-in uses the AWS Serverless Application Model (SAM) to generate build artifacts and CloudFormation templates to deploy AWS resources. I may stretch and try out the Cloud Development Kit (CDK) but many of the AWS Glue CDK constructs are still listed as ‘experimental’ given that CDK is still pretty new.
- Compute will probably be primarily backed by serverless solutions such as AWS Lambda and AWS Glue ETL Jobs. I will be making use of AWS Step Functions to implement a state machine to serve as the data quality auditor. There will probably be a number of Simple Queue Service (SQS) queues to help manage compute processing.
- Data Streaming will be handled by Kinesis Data Streams for writing to a data stream and then Kinesis Firehose to move the data to S3. I have always been intrigued by Kafka but using something like Amazon Managed Streaming for Apache Kafka seems like overkill for this project.
- Analytics will be supported by AWS Glue Data Catalog and AWS Athena to keep with a serverless model.
Starting Point
I have been using Finnhub’s API for obtaining stock data. Per the API documentation, I can get live stock quotes or I can get “candle” data to grab historical quotes.
Right now I am experimenting with a local client to get an understanding on how the API responds. Once I get something basic written to move data from the API to a data stream, I will move the code to Github and blog my progress.
I suspect much of this will change along the way… so here we go!